為了提供我 Data Science 需要的資料,來準備爬蟲程式吧!
不想特別去寫 Python,所以就用 Javascript 吧!
Kirby: 我們發現在過去鐵人賽的文章中,
很少人 嘗試 Python 以外的選項!?
這個小系列分作三個部分
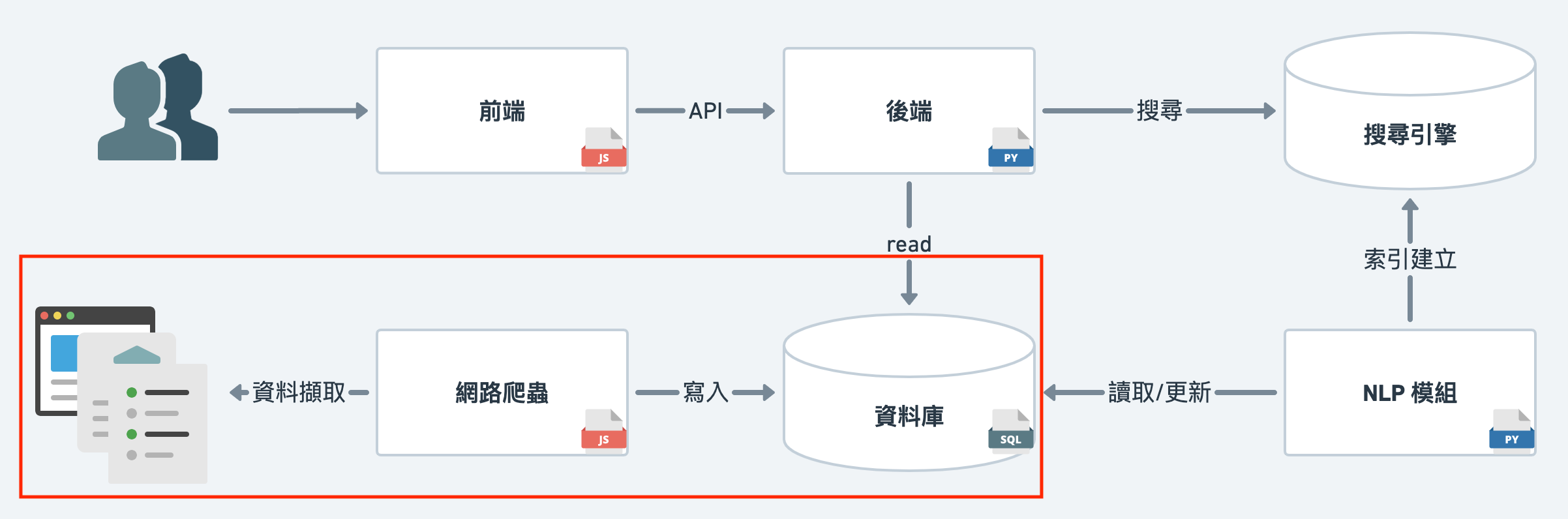
這邊先進行名詞解釋,方便後面同步。
Scraping
專門指擷取網頁資料,人工的 Copy Paste 也算在此類。
把資料擷取下來之後,經過分析或儲存後,使資料在接下來被近一步使用。
Crawler (網路爬蟲)
搜尋引擎為了搜集資料、建立索引,
有撰寫機器人,自動化搜集網路上資料的需求。
許多大型的搜尋引擎像是 Google, Bing, Yahoo 等,
皆有各自的機器人,並會爬過每一個頁面跟每一個連結,比較非目的性。
有時也被稱為 spider。
Scheduler
預先設置好在某個時間點執行某項任務的腳本。
也可以稱作 排程。
我們的目的只需要鐵人賽文章,
因為有明確的目標加上幾乎固定的資料集,
這邊就不用特別沿著連結慢慢爬,
直接對確定的目標進行資料擷取,
然後每週固定跑一次即可。
再來設計程式流程,
整個資料搜集分做兩大塊,crawler job 跟 extracting。
實作的 crawler code 和 github action script 都在 github repo 中。
為了不佔篇幅,這邊直接給最後的思路 (pseudo code),
同時,可以同時參照下方 wikipedia 上的 crawler 架構圖。
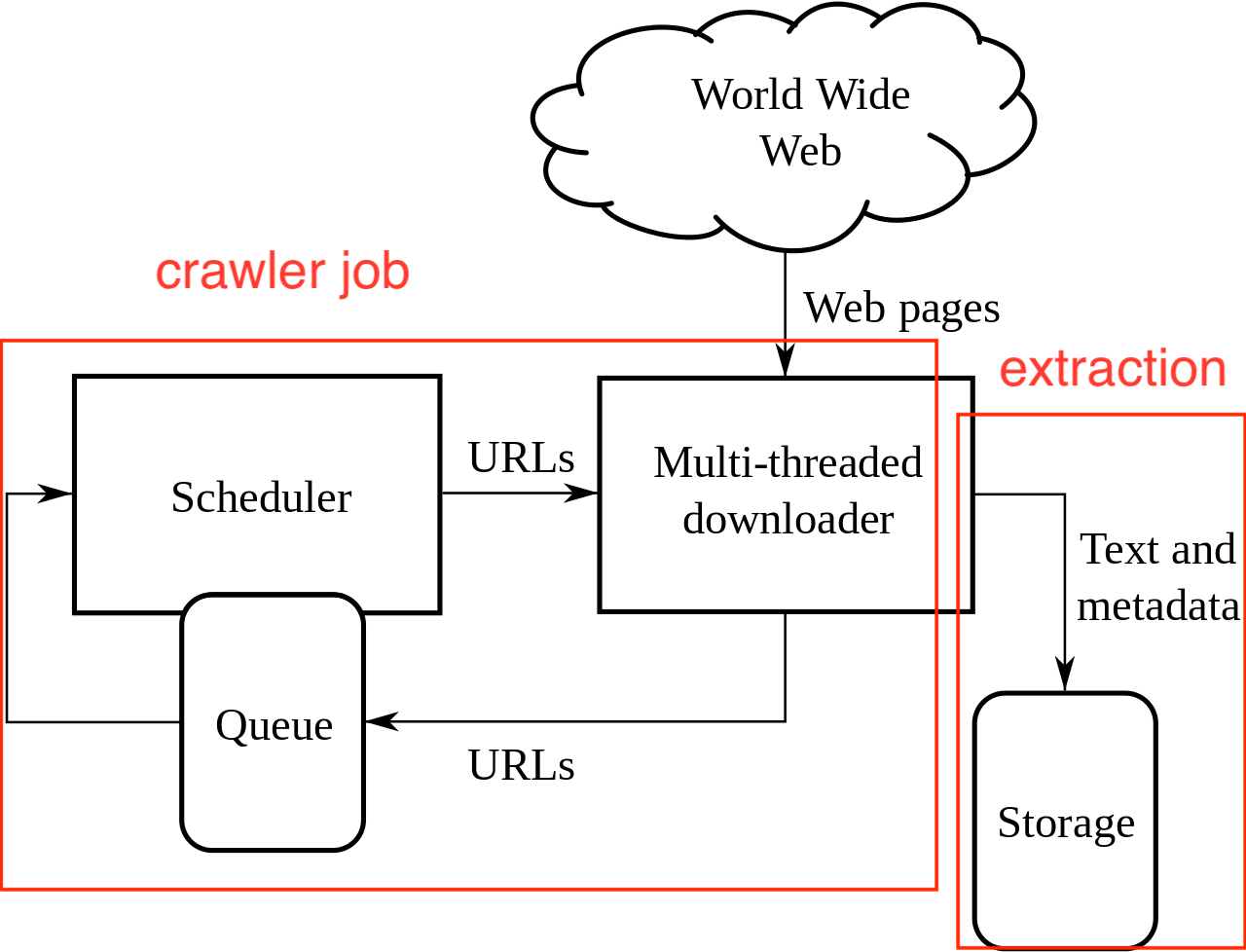
另外,我的目標是 盡可能減少不必要的程式碼,
所以 crawler job 會透過 GitHub Action 處理。

